A PM's Guide to Building with LLMs, Part 2: Advanced Techniques.
Now that you have a basic setup, make it better for your own use case with data, pipelines, and feedback.
Pieter van Noordennen |

A PM's Guide to Building with LLMs, Part 2: Advanced Techniques.
“When robots threaten to take your job, be the one who works on the robots.” —Simon Johnston, MIT Professor and former Chief Economist at the World Bank
You’re now a bona fide ChatGPT expert and have an understanding of prompts, the model landscape, and basic building blocks.
But you’ve noticed that for your specific use case, the AI is a bit lacking. The answers are kind of generic. It tends towards a voice that’s too enthusiastic, verbose, and, well, ChatGPT-ish.
It’s cool, but it doesn’t really work for your needs. And its somewhat underwhelming compared to the demos you see online or at Dev Days.
That’s because the product teams developing the best AI applications are doing a lot more than just wrapping the OpenAI API in a thin layer of UI and shipping it to customers.
Let’s get into some of the more advanced techniques on how teams are doing this.
This is Part 2 in my series on building products with AI. This series is targeted at product managers and growth teams looking to use AI to enhance product and operations, but who don’t know where to start.
**Note:**I’ll finalize the Table of Contents once I’m deeper into the series.
- Basic Building Blocks
- Advanced Techniques: Agents, Chains, and Retrieval (this article)
- Model Evaluation and Why You Need It
- Model Eval Tools and Techniques
- Pre-Production QA
- Post-Production LLM Observability
Creating Services: Agents, Chains, and GPTs
If you’ve done platform work in the past, you are probably familiar with microservices architecture. If not, you are at least familiar with engineers building some kind of service (an API endpoint, application, web app, etc.)
As we’ve said, developing with LLMs is a bit different than traiditional software development. And Agents can be said to be the “service infrastructure” of LLMs. Agents are autonomous, single-threaded task rabbits. They differ from simple LLM calls in that they have a suite of Tools they can pull from (think: web search, math, SQL queries, Zapier) and that they generally have a single task to perform, like finding the weather in a given city on a given date or identifying that one meme I’m thinking of but can’t quite describe.
Agents are somewhat a construct of the LangChain that popularized them, though the concept long pre-dates LangChain and even ChatGPT. In early November 2023, OpenAI released their GPTs, which can be understood as OpenAI-ecosystem-specific, no-code required agents.
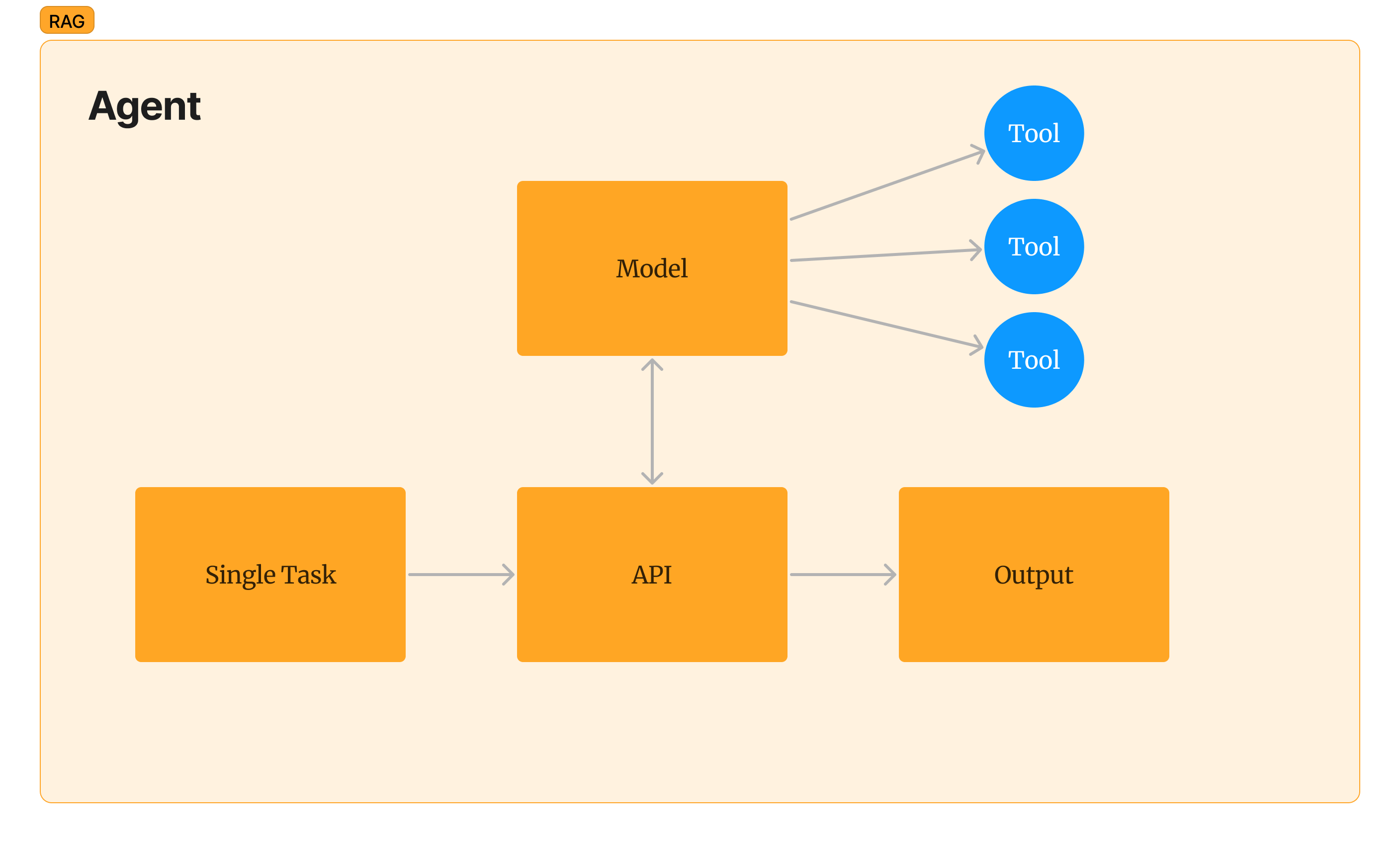
For my own understanding, I just think of agents as little worker bees that can take succinct tasks and go do work on my behalf.
But how do you manage them and get them working together? Enter Chains.
Chains — another LangChain-derived concept — are pipelines of agents or LLM calls that can be strung together to achieve a more complex outcome.
One of the earliest examples I build was a Movie Dialog writer. I had a few prompts I’d been testing just for fun.
- Prompt 1: Given a character name, generate a universe for that character.
- Prompt 2: Given a character name and universe, generate the character’s background.
- Prompt 3: Given a character name, unvierse, and background, generate a second character.
- Prompt 4: Given all of the above, generate lines of dialog in a conversation between the two characters.
Now here, I was just using prompts instead of agents, but the affect was that rather than generating each step individually, I could just pass in a single user input (“Character Name”) and get a full blown story with initial dialog.
Thinking through more real-world use cases, you could easily envision a development task where you need to take unstructured data, parse it, format it, and put it into tables.
Such a chain might look like:
- A - Prompt: For a given user question, suggest an API endpoint for public government data that could answer that question.
- B - Agent: Use the response to poll the endpoint and return some data.
- C - Agent: Use the Pandas data library to convert the JSON into tabular format.
- D - Prompt: Given this tabular data, map the columns to this new schema for my database.
- E - Agent: Use SQL to import the data to a new table in my desired schema.
From a UX persepctive, user inputs a question and gets a database populated with useful, structured info.
It’s also worth noting that Agents and Chains need not be so scripted. They can call each other automonmously or create new agents to perform tasks. For instance, your prompt in step D above might want to create a new agent whose job it is to validate the data schema before completing the task.
These are known as “Orchestrator Agents” and are often where agent-based chains succeed or fail — sometimes returning an answer and amazing their developers, and sometimes spinning endlessly in loops of circular logic.
It should be said that it is still very early days for agents and chains, and the autonomous visions of many a startup founder have been dashed by “stupid robots” who endlessly try to repeat the same failed tasks.
Adding your own data: RAG, Grounding the Model, and Fine-Tuning
ChatGPT is one of the great horizontal product successes of recent history. It is broadly applicable across almost any use case or subject. But that generality can also be a limitation for businesses, which differentiate through specialization.
Businesses generate data specialized to their use cases and customers. This data can be used to fine-tune an LLM model, creating, in effect, “MyCompanyGPT”, a model that can do tasks like customer service, marketing, and even finance as if it were one of the company’s subject matter experts.
For that, you need what’s called “retrieval-augmented generation”, or RAG for short.
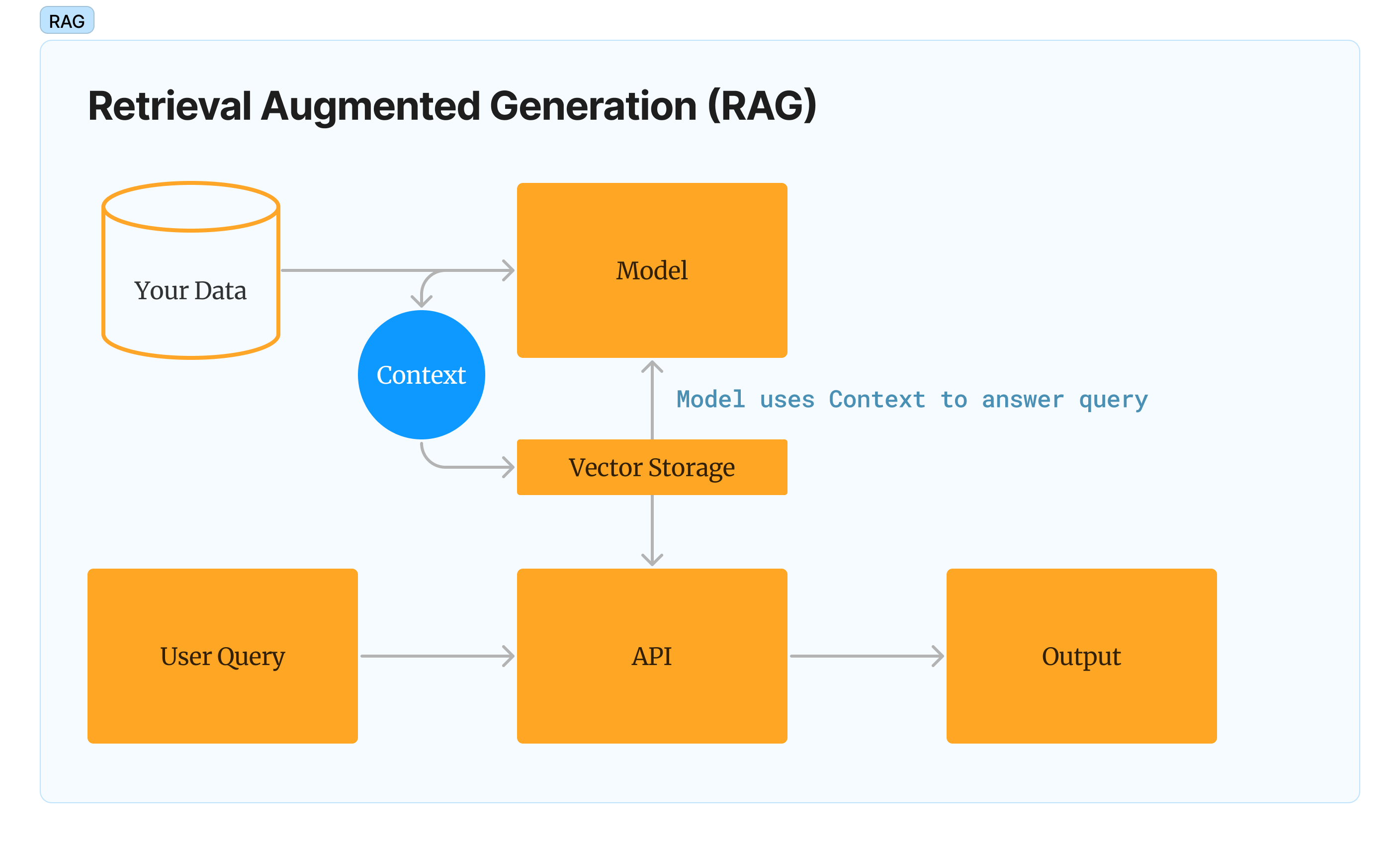
RAG is pretty simple in concept and easy to build as a PoC: You send your data to the LLM and get back “embeddings” — think of them as markers the model can use to earmark your particular information. You can then use the model to answer future user queries, either exclusively from that data or with its broader generalized context.
Traditional RAG (that is to say, the RAG models of last month) used purpose-built databases called Vector Stores to store embeddings — Pinecone, Chroma, FAISS, and Lance being some of the popular options. With the recent AI fervor, more traditional datastores like MongoDB and Postgresql have gotten in the vector storage game. And OpenAI’s latest release (as of publication time) of GPTs has a RAG capability built in (this is what’s happening under the hood when you upload a reference document or tell GPT to browse a website).
Building RAG isn’t all that difficult and as a PM, you don’t have to think too deeply about what’s happening under the hood. Evaluating RAG is a whole other story. In particular, there’s some great research by Gregory Kamradt and others on how the accuracy of retrieval — that is to say, can the LLM find certain facts within a given document reliably — suffers in larger context windows or larger documents.
I’ll get more into evaluation in future posts, but know that building a RAG model is only half (or one-tenth) of the battle. Plan to spend time and resources on creating a reliable QA framework.
If RAG is unsuccessful for you, you might have to start thinking about “fine tuning”. This concept takes the notion of grounding a model in your data even further, training a foundational model on a corpus of data to better direct results.
Fine-tuning comes with a cost, and a fine-tuned model will require maintenance over time. Small models, like Mosaic’s 7B parameter model that caused DatBricks to acquire the company last year, is one such example. Small models can be fine-tuned more cheaply than their larger, 40B parameter brethern.
If fine-tuning comes up in your discussions with the tech team, be sure to have some friends on the data science side nearby, and ask yourself if that’s a path you really want to go down.
Kaizen for Models: Constant Improvment through RHLF and Humans-in-the-Loop
Speaking of evaluation, accuracy, and improvement, it is still true that humans provide the most reliable feedback on content produced for, well, humans. Data science has long had “labeled data” (i.e., human-categorized examples on which to test and train ML models), and LLMs are no different. Those “thumbs up” / “thumbs down” voters you see in Chat UIs are an example of crowd-sourced, human-in-the-loop feedback. The fancy LLM name and acronym for this is “reinforcement learning from human feedback”, or RLHF.
LLMs respond well to RHLF and fine-tuning. The challenges for product teams come in both implementing it and scaling it.
Implementing RHLF
Since you don’t have the ability to fine-tune the core SaaS LLMs (GPT-4, Claude, Bard, etc), RLHF mostly applies if you are building a fine-tuned model off of an open-sourced Foundation Model (like LLaMa or MosaicML), or if you’ve built your own foundation model (in which case, again, you don’t need my adivce).
Actual implementation of RHLF is best left to a conversation with your data science team, but as a PM, be thinking about how best to collect feedback, both during your QA runs and crowd-sourcing it from customers. Note that not all customer feedback is going to be of the same quality, and you may need to get creative.
One example from my past is when we tried to train a photo scoring model. Our initial instict was to take in user feedback in the form of “Likes” on photos. After all, we had the data, we have millions of users, and it was easy to get. But the most liked photos tended to be grotty bathrooms or blurry shots from the hotel bar, not exactly the vacation inspiration we were looking for. Our next iteration had our college interns rank photos. But the interns loved pools and not much else, thus the model over-corrected for anything blue: painted walls, bedspreads, traveler’s clothing. Finally, we hired a team of five professional photo editors to rank images for us. The results were great and it didn’t cost us a ton.
Point-being, have a strategy for getting human feedback, and think critically about the feedback you’re getting.
One last thing on RHLF is that there’s a lot of new research in the space on using LLMs to provide feedback on LLMs.
The New Stack and Ops for AI, OpenAI Dev Day
This video from OpenAI’s Dev Day in November 2023 shares their experiments with using GPT-4 to evaulate results of GPT-4, and even using it to fine-tune a faster, cheaper GPT-3.5 model to do just feedback. There’s lot of open space ahead in the world of adverserial AI, synthetic data, and self-healing systems. For now, it’s just a space to watch and perhaps experiment if you are running into problems scaling human feedback for your models.
Conclusion: On the Eval
You can see where all of this is heading: The need for evaluation. LLM applications, like any other data-driven exercise, have the garbage-in, garbage-out problem, no matter what tools and techniques you use to make them.
In the next section, we’ll use a real-world example (courtesy Monty Python’s “The Holy Grail”) to build a basic Model Evaluation framework, seeing if an LLM can reliably answer the age-old question:
What is the air-speed velocity of an unladen swallow?
Til next time. Keep building.